2024年の自転車への課金
たまに乗っている自転車への課金。年間通してみると40万いってないくらい・・・?
Roval RAPIDE C38
www.specialized-onlinestore.jp
ホイールを買った。エントリーグレードのカーボンホイール。
+でチューブレスにして乗っているが、正直TPUチューブみたいな軽量チューブとGP5000みたな運用の方が軽くてよいかも?という感じ。
スターラチェットという、ホイール内部のパーツを変えると、ちょっとエネルギー効率が変わるのでそれも追加で購入。
POWER EXPERT WITH MIRROR
www.specialized-onlinestore.jp
サドル。
B02B スペシャライズド パワーサドル用Olight SEEMEE30ホルダー - メルカリ
メルカリShopsで売っている、サドル用のライトホルダーと組み合わせて使っている。
ROVAL RAPIDE ROAD BAR
www.specialized-onlinestore.jp
ハンドルもなんかエアロハンドルほしくなったので、課金。
中国株を買おうかなと思って、中国について調べている
米株と連動していないアセットが欲しい
最近、米株が絶好調な理由は、生成AIなどのAIブームでマグニフィセント7(GAFAM + nvidia + tesla)の株価が伸びているからだと言われている。
ただ、正直、現時点の生成AIにそこまでのインパクトがあるとは思えず、ガートナーのハイプサイクルでいえば今が絶頂なのでは?という気もしている。

引用元 : https://www.gartner.co.jp/ja/newsroom/press-releases/pr-20231012
今後の米株の伸びはもちろんあるかもしれないし、それには乗りたいが、一方で、リスクも高いのではないだろうか。
だから、できれば米株に連動しない(できれば生成AIの次にちゃんと伸びる)アセットが欲しい。
中国株は選択肢になるのか?
そこで、ここ1年の米株(NYダウ)
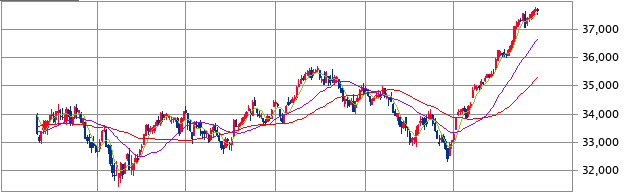
と中国株(香港ハンセン)

を見比べると、米株は爆上がりしている一方、中国株は下がっている。
何故中国株が下がっているかというと、中国はかつての日本と同じように高度経済成長を経て不動産バブルを起こし、弾けたから。
だけど、景気回復しているようにも見えるし、配当利回りもめちゃくちゃ高いので、割安な株を一部拾っておきたい気持ちもある。
日本のように、失われた30年の低成長時代が来るリスクはあるが、記事に書かれているように、全然予測できる問題ではない気がする。
もっとも今の米国に対する楽観と中国に対する悲観は行き過ぎている恐れは否定できない。やがて市場関係者の見通しが修正されるとともに、歴史的な米経済の上振れと中国経済の下振れは揺り戻しに見舞われるだろう。
ただ投資家が今年になって中国から大量に資金を引き揚げたこと、米中の10年国債利回り格差が2007年以降で最大に開いたこと、そして人民元が同じく07年以来の安値に接近したことには、いずれも相応の理由が存在する。
逆張り派としては、下がっている時に買いたいが・・・・。
2023年振り返り
仕事
5年間勤務した会社を退職した。非常にいい会社だった。本日最終在籍日。
元々、前々職のベンチャー企業で担当していた部門がうまく伸びなくて潰れて、やりたいこともなかったので業務委託で仕事を始めたのがスタートだった。
あまりにもいい会社だったのでそのまま入社させていただいて5年ほどお世話になった。
(業務委託の契約終了間際に癌の告知を受けて、その後のプランを白紙にせざるを得なかったので、退院したら入社させて貰えませんかね・・・・・?ってダメもとで頼んだら入れてくれたので本当に神のような会社だった・・・。)
自分が仕事を始めた時、創業5年目のIT企業だったけど、福利厚生や給料も充実していて、上昇気流に乗っているような感覚。自由みたいなものがある環境だった。
というわけで大変良い職場だったのだけど、元々ちょっと飽きやすい性格 & 色々しんどい時期が続いていたので、5年くらい経ったら他のことを考えようかな、と薄ら思っていたので辞めることにした。
日本のIT企業で大きなところに行っても、辞める必要なかったじゃん?みたいになるので、ちょっと業種や文化の違う会社で仕事をしてみようかな、と思っている(といってもプログラマーは続けるので、それほど差はないかもだけど)。
やっていたこと
今年は、決済手段の拡充や、アカウント体系の整理、アクセス負荷対策、みたいなgoのbackendの実装をやっていた。
趣味
前半は結構運動していたけど、中盤以降運動不足で失速した感がある。去年完走できていたトライアスロンのオリンピックディスタンスもリタイアしたし・・・。
ただ、やっぱり登山や自転車の長時間の有酸素運動は、明らかに体調が良くなるので、来年はちゃんとやりたい。
雲取山
GPSがバグってる pic.twitter.com/CXYfQ0aWuX
— ne (@sodefrin) 2023年1月3日
滝子山
今日のルートはほとんど人がいなくて登山道に落ち葉が40cmくらい積もってて雪みたいで楽しかった。多分秋に行くと絶対に良い。 pic.twitter.com/nOYbIRFp8B
— ne (@sodefrin) 2023年1月15日
冬の金峰山
金峰山頂上近くまで来たけど、森林限界超えの冬山怖すぎ&同行者が疲れてたので戻ってきてしまった pic.twitter.com/3eulh0KCn7
— ne (@sodefrin) 2023年2月4日
渋峠サイクリング
5月の渋峠は日本で一番良いサイクリングスポットの一つかもしれん pic.twitter.com/xaAlVkA33b
— ne (@sodefrin) 2023年4月29日
谷川岳
— ne (@sodefrin) 2023年8月27日
伊豆大島サイクリング & ランニング
day2-3。自転車に乗って島を一周したり、真ん中の山に登ったり、海沿いのトレイルを走ったりなどしました。 pic.twitter.com/v4qN5grOCU
— ne (@sodefrin) 2023年10月22日
高尾山
久しぶりのリハビリ pic.twitter.com/HytKdaaizP
— ne (@sodefrin) 2023年12月17日
丹沢
リハビリ pic.twitter.com/h0SIHlcASV
— ne (@sodefrin) 2023年12月30日
多分ツイートしてないのも結構あるので、振り返ったら結構運動していた・・・?ような気もする。
ぷよぷよ
何気に結構ゲームしていることが判明した pic.twitter.com/7gOZlWPA0U
— ne (@sodefrin) 2023年12月19日
たまにしていたけど、だいぶ弱くなったので、ガチ対戦という感じがしない。
健康
今年は近年稀に見る酒浸りの一年だった。幸にして今のところ致命的な健康障害はない。10月頃に50日くらい禁酒していたのだけど酒は飲まないと明かに健康的になることがわかった。
来年は飲酒はほどほどにしたい(でも完全な禁酒は無理かも)。
私生活
昨年から、地獄のような婚活(?)をしていた。
自分の場合、癌で手術したことあるんだよねーとか親とほぼ連絡とってないんだよねーとか話すと「ちょっと結婚は考えられない」と言われて付き合う前でも後でも割と振られた。
自分のことをあまり話さないことがうまくいく秘訣、という感じがして結構しんどかった。
が、ある程度落ち着いたので来年は、結婚するかもしれない。多分。
投資
まだ損失確定してないのかなりあるけど、今年、損失少なくてちょっと笑ってしまった pic.twitter.com/pC4pAc9OIy
— ne (@sodefrin) 2023年11月27日
個別トレードは、ほぼほぼ全部のポジション整理して最終の確定損益が↑(積立てて放置しているインデックスは除く)。+で配当が10万くらいあった。
来年はもうちょっと上を目指したい。
まとめ
というわけで来年は、
- 仕事は全てではないので無理はしない
- 週末は登山やサイクリングに行くと健康に良い
- 酒はほどほどに、とはいえ楽しいなら飲む
- 徐々に給料の伸び率 << 投資の収益にして仕事への依存度を減らす
- 身を落ち着かせる
あたりを目指します。
基盤モデル(の応用領域)について調べている
*浅い理解でざっと調べている状態なので間違いがあるかも
基盤モデルとは
基盤モデルとは 「大量で多様なデータを用いて訓練され, 様々なタスクに適応(ファインチューニングなど)できる大規模モデル」 のこと
つまりChatGPTは基盤モデルの一種。
www.slideshare.net
- 元々、翻訳機能のために開発されたtransformerというモデルを利用している
- 基本的には、次に続く単語が生成される確率を推定する
- モデルの大きさと学習量を増やすと劇的に性能が向上した
- あまりにも人間らしいresponseが返ってくるため、汎用人工知能の実現可能性が検討され始めた
基盤モデルと自動運転
位置推定の自動運転
2008年の自動運転で(ほぼ)アメリカ横断が達成された時、そのキーとなった技術は機械学習ではない、LiDARというセンサーだ。
LiDAR+自己位置推定は悪くない。実際に私も実装してみたがサクッと動いた。ある程度想定された環境下なら極めて実用的だ。自己位置推定をLiDARなどで行って経路計画を立てて、もし前方に障害物があれば止まるなり回避ルートを計画すれば良い。
過去の自動運転では基盤モデルは使われていない。これは、運転というタスクがある程度限定的な操作で、位置推定の精度が高ければ動くから。
画像認識などで部分的に機械学習は利用されているものの、コアのアルゴリズムはルールベースの実装に近い。
このアプローチはAutowareなどのOSSとしてすでに実装が公開されている。
ただし、このアプローチで実現できるのはL4まで。より一般的な自動運転の実現には、トラブル時のコーナーケース対応などが必要で、位置推定を中心としたロジックでは実現が難しい。
基盤モデルの自動運転
L4の自動運転はすでに実用段階だが、より柔軟な判断が要求されるL5の自動運転には、運転という操作に限定されない汎用的な知能に近いものが必要 -> それにLLMが使えるのでは
自動運転における基盤モデルの活用に関して以下のアプローチがある
- LM-Nav : 基盤モデルと複数のモデルを組み合わせてナビを実現する
- PaLM-SayCan : 基盤モデルが指示を具体的なタスクに落とし込んで順次実行していく
- 運転データのファインチューニング : 運転データをLLMに覚えさせる
End-to-Endの自動運転学習
Teslaは、自動運転に対してもend-to-endの機械学習で自動運転専用の基盤モデルの作成を試みたが、今のところあまりうまくいっていないように見える。(詳細はあんまりわからない)
基盤モデルとロボティクス
“is training a large neural network on a very large dataset a feasible way to solve robotics?”
大きなneural networkで非常に大きなデータセットを学習することでロボット工学を解くことは可能なのか?ロボット工学では、さまざまなタスクをよしなに実行してくれる汎用的なロボットの実現は聖杯とされていたが、近年のLLMの性能により、実現可能性が出てきた。それについてのさまざまな意見のまとめ。
賛成意見
- コンピュータビジョンと自然言語処理で可能なことはロボティクスでも有効なはず
- すでにある程度の実績が出ている -> GoogleのRT-XとRT-2は、一定の成功を収めている
- 基盤モデルは、乗るべき波
- ロボットが行うべきタスクは比較的限られているため、大規模なモデルのトレーニングが有効
- 出力可能なデータより、頻繁に出現するデータの空間が狭い場合、一般に機械学習は有効だと考えられる
- 基盤モデルでロボット工学に「常識」を導入できる可能性がある
- ロボットのタスクのコーナーケースはあまりにも広いため、「常識」的な推論が有効だと思われる
反対(そもそもできないのでは?という意見)
- そもそもロボット用のデータが少ない
- ロボットの形はさまざまなので、データがたくさんあっても学習が難しい
- さまざまなシチュエーションでロボットを活用させる必要がある
- ロボットデータセットの学習にどれだけのコストがかかるかわからない
反対(できたとしても・・・・という意見)
- 99.X問題とロングテール:コーナーケースが広すぎるロングテールなので、高い成功率を実現するためには、現実的ではない学習コストが必要になる
- 既存のLLMなどの基盤モデルもその水準には達していない
- 自動運転では基盤モデルはまだ十分な成果を出していない(機械学習ベースのL5の自動運転はまだ達成されていない)
- 機械学習は非常に大きなデータを正確に出力するのが苦手
- 特にロボットでは誤差の積み重ねを補正する必要があるので難易度が高い
RT-1, RT-2, RT-X
robotics-transformer2.github.io
Scaling up learning across many different robot types - Google DeepMind
RT-1
RT-1の論文が長くて、一旦概要だけこちらで流し読み。
- RT-1は自然言語のtaskと画像をもとにbaseとarmの操作アクションを生成する
- RT-1は人間がリモート操作で収集したデータに自然言語のannotationをつけたものを使って教育された
- Transformerでtokenizeされた画像と指示を学習する
- PaLM-SayCanとRT-1を組み合わせることで、ロボットに抽象度の高い話指示を出してtaskの系列を実行してもらうことができる
RT-2
あまり機械学習の詳細を理解できていないので詳細はわからないが、他の基盤モデルをベースにロボットの操作情報をfine tuningした・・・・?
RT-X
RT-1とRT-2は、特定のロボットでデータを集めたが、RT-Xはいろんなロボットでデータを集めた。これによって性能が向上した。
まとめ
この領域でのアプローチは主に以下の3つ
- 他の基盤モデルとRT-1のような基盤モデルを組み合わせる
- 他の基盤モデルをfine tuningする(これはよくわかってない)
- end-to-endで新たな基盤モデルを作成する(これもよくわかってない、teslaがやろうとしたアプローチ・・・?)
また、機材毎のデータを増やすことで、機材の性能差を少なくすることができる
機械学習の過去の研究成果からすると、3 > 2 > 1になりそうだが、データ量の問題があるので3を現時点で実現するのは難しく、2が今のところ現実解?
3が実現できるだけのデータがあったとしても、精度という意味ではまだ十分なものが得られていない(CVやNLPなどの既存分野も同様)
と思って調べてたけど、これが一番詳しい感じがする
AIとロボットについて調べている
目についたものを書き殴っているので取り留めはない。
Tesla
There’s a new bot in town 🤖
— Tesla Optimus (@Tesla_Optimus) 2023年12月13日
Check this out (until the very end)!https://t.co/duFdhwNe3K pic.twitter.com/8pbhwW0WNc
teslaはEVや自動運転の会社だが、汎用的な人型のロボットの開発もしている。
説明されているtech stackはほとんどロボットというより自動運転のものな気がするので、tesla的には自動運転とロボットをそれほど区別していなさそう。
Tesla Bot
Tesla Botは、ロボットのハードウェア。二足歩行人型の汎用的なロボット。
FSD Chip
FSD (Full Self-Driving) Chipはlevel 5の自動運転を目指すためのチップ。CPUとGPUとNPUが乗っている。EdgeでAIの推論し、自動運転を実現するためのチップ。
Dojo
AIの学習をするためのチップ(Dojo Chip)とそれを効率的に機械学習に活かすためのデータセンターのシステムを開発している。
Neural Networks
センサーからデータを集めてたくさん機械学習をしている。一般的な画像認識などの学習。
Autonomy Algorithms
自動車の運転計画を作成する機械学習。画像認識の結果と位置情報、スピードなどを組み合わせて学習するように見える。
Code Foundations
latencyや正確性を最適化するために低レイヤーからスクラッチで開発している。linuxベースらしい。だけど書かれている内容はRTOS的な安定性を追求しているようにも見える。
Evaluation Infrastructure
継続的な機能の改善のためにアルゴリズムの評価基盤が必要。
ROS (Robot Operation System)
ロボットに接続されるセンサーなどを抽象化して操作可能にするための通信ミドルウェア。センサーとの接続などの低レイヤーの機能は、layer切り分けて開発しないと結構辛いものになりがち。センサー類とやりとりするためのデファクトスタンダードに近い通信規格&middlewareというイメージ。汎用計算機上でも動くし、cross-compileして組み込みのRTOSでも動くようにできるっぽい。
cross-compileを想定した独自のbuild toolが付属していて、それのbuildにハマりがち・・・・・・・。webの開発に慣れていると、buildが難しい環境は勘弁してくれという気持ちになるけど、組み込みの世界はSoCのアーキテクチャが変わるとcompilerも変わるので致し方なしという気も。
1X
OpenAIに出資されているロボットメーカー。tech stackなどは特になく詳細分からず。AIはデータセンターの中で発達してきたが、外とインタラクションするためのinterfaceはまだ未発達。人とコミュニケーションするためには、人型が一番良いinterface。という主張をしている。
Turing
teslaを超えることを目指す日本の自動運転を目指すスタートアップ。
完全自動運転EVの量産ができたら、直ちに完全自律型ヒューマノイドの量産に取りかかるべきなんだよな。
— 山本一成🌤️TuringのCEO (@issei_y) 2023年12月12日
人が人を工学的に作ることは人類のアルティメットゴールの一つだからな。
LLMを使って自動運転を行ない、(1) 空間認識 (2) ルール遵守が必要な状態で、正確な判断ができるかを計測。既存手法(not LLM)との比較はなく、LLM間の比較のみだったので、どれくらいLLMに優位性があるのかは不明。 自動運転のコーナーケースは大きなロングテールなので、従来の手法ではそれらを十分にカバーできるだけのデータセットを用意することが難しいが、LLMを使えば解決できるのでは?という目的意識がある。
Modular Monolithについて調べている
開発の生産性と組織とアーキテクチャ
ソフトウェアエンジニアの開発の生産性は、開発組織やアーキテクチャと無関係ではないと感じることが増えた。以前は、プログラマーとしてあまりにも未熟で具体的な実装に反省点がたくさんあった(もちろん今もある)。最近はそれ以上に、組織とアーキテクチャの不一致により生じる負債の方が致命的だと感じることが多くなった。
組織論としてのmicroservice
「Microservicesは組織論」と言われるようにMicroservicesアーキテクチャの究極的な成果物は新たな組織図である.新たなアーキテクチャに基づく新たなチームの編成,組織の再構成を狙うのが大きな目的である(逆コンウェイの戦略,Inverse Conway Maneuverなどと呼ばれる).
アーキテクチャにmicroserviceを採用していても、技術や組織が伴っていないと開発のオーバーヘッドが大きくなったり、逆コンウェイの法則でコードが複雑化していくデメリットの方が大きい。思うに、整合性を維持するためにTCCパターンやSagaパターンを採用しなければならなかったり、サービスごとに実装を独立させる分だけコードやインフラの量が増えるというオーバーヘッドは技術の問題で、昔はそれらの知見が不足していたため技術に対する反省が多かった。ある程度知見が溜まってくるにつれて組織的な問題の方が気になり出すというのは自然なことだと思う。
modular monolithは解決策なのか
前述した技術視点での問題は、monolithではあまり発生しない問題だと思うのだけど、組織の問題はmonolithでも起こりうる。事業会社である以上、開発人員の拡大や縮小などは当然起こるからだ。そういった際のアーキテクチャの変更としてmodular monolithを採用するのだろな、と思って各社どのように整理しているのかいくつか資料を調べていた。
ドメインの境界毎にlayered architectureのmoduleに切り出し、module間は公開されたinterfaceを通じた呼び出しのみを許可というのが概ね共通見解。一方で、サービスの定義の単位次第では、microserviceと同じように整合性の問題が生じる場合もあると感じている。そういう場合、DBのトランザクションをmodule間で共有するのか?TCCやSagaパターンを採用するのか?といったことに触れた記事はあまりなかった。
疑問としては上のslideに近いが、実際どのように整理されることが多いのだろうか。調べた範囲での自分の意見だと以下の整理が多くの場合現実的だろうか?と思った。
- TCCやSagaパターンが必要なservice分割はできる限り避ける(それによってコアのtransactionを処理しているサービスがある程度まで大きくなることは許容する)
- 切り出しやすい依存関係(非同期なsubscriberや参照系のデータの組み立てなど)は積極的に切り出していく
- DB Transactionはmodule間では共有しない
最近、modular monolithという言葉はよく聞くけど、具体的な実装レベルの話はあまり出ていなくて残念・・・・。
プログラミング TypeScriptの読書メモ

TypeScriptの入門書。TypeScriptの文法をそんなにちゃんと勉強したことがなかったので、学びが多くあった。
TypeScriptは、JavaScriptに後から型を追加したため、他の言語には多くない柔軟な型表現を持っていて、それはメリットにもなる反面でTypeScriptらしい書き方を学ぶコストが高くなってしまっている気がする。
多くの多くの静的型付け言語では、意識しなくても型安全になるけど、TypeScriptではそうではない部分が多くある。
一方で、多くの言語でいい感じに書けない処理をTypeScriptは型安全に抽象的に記述できるのが強み。
習うより慣れろ的側面が多いと感じてしまうので、他にもうちょっと実践的なコードを写経したりする必要はありそう。
個人的には明かに便利やんという文法と、何でこんな挙動すんねんという挙動が入り混じっていてうーんという感じ。
型について
anyとunknown
any
anyを使うと型が不明なまま任意の操作を許可してしまう。実質pureなJavaScriptと同じ挙動をすることになるので避けるべき。
unknown
型チェックを行うまで操作ができない。anyよりも安全。止むに止まれぬ理由がある場合はanyよりunknownを使う。
const
constを使うとリテラル型が定義される。特定の値しか入らない型。
object
typescriptのobject型はかなり特殊。フィールド定義までが型になる。
let a = { x : "xxx" } // { x : string} という型になる
型推論後にfieldを足したり減らすような操作はerrorになる。
空object {} の扱い
{}とObjectはガバガバなのでなるべく使わない。objectもできれば使わない。
stringとStringの違い
stringはプリミティブ型、Stringはinterface。
合併型と交差型
objectに適用した時にちょっとややこしい。A|BではAまたはBのプロパティを備えているobject。
A&Bでは、AかつBとなるようなプロパティを備えているobject。
type A = {a: string}
type B = {b: number}
let d : A | B = {a: "a"} // OK
d = {b: 1} // OK
d = {a: "a", b: 1} // OK
d = {a: "a", b: 1, c: 1} // NG
let c : A & B = {a: "a", b: 1} // OK
c = {a: "a", b: 1, c: 1} // NG
配列
空array [] の扱いがめちゃくちゃ特殊。定義されたスコープではなんでもpushできるけど、そこを離れると型推論が終わり、任意の型を追加することができなくなる。
タプル
固定長の配列を定義し、それぞれのインデックスの型を宣言可能。可変調の要素を定義することも可能。
let x: [number, string] = [1, "a"] let y: [number, number?, number?] = [1, 1, 1] let z: [number, number?, ...number[]] = [1, 1]
nullとundefined、void、never
nullとundefinedはほぼ違いがない。慣例的には、undefinedは未定義。nullは欠損。
voidは戻り値を返さない関数の戻り値。neverは決してreturnすることのない関数の戻り値。
enum
enumは値でもキーでもどちらでもアクセス可能。しかしキーでアクセスする場合は安全ではない挙動があるので、const enumを利用した方が良い。
ただし、外部ライブラリに公開する相対にconst enumを使うと、問題が起こる可能性があるので、その場合は通常のenumを使う。
またenumの中に数値があるとenumが安全ではなくなるのでstringで定義するように注意する。そもそも使わない方がいいのでは・・・・?
関数
関数の中でのthis
JavaScriptでは、classのmethodとして定義されていない関数にもthisが存在する。このthisは脆弱性を持っているので、methodの場合以外はなるべく使わない。
function date(this: Date) {
return this
}
date.call(new Date) // OK
date() // NG
date(new Date) // NG
↑のようにthisの型を指定することができる。この場合、thisがDate型で定義されていない場合、呼び出しが失敗する。
ジェネレーター関数
イテレーター
全然知らん話題
オーバーロード
type Reservation = string
type Reserve = {
(from: Date, to: Date, destination: string): Reservation
(from: Date, destination: string): Reservation
}
let reserve: Reserve = (
from: Date,
toOrDestination: Date | string,
destination?: string,
) => {
return ""
}
型が合体するのすごい。
ジェネリック
Tをつける場所によって動き方がちょっと違う。まあ使う時に読めば良さそう。
クラスとインターフェース
アクセス修飾子
public : どこからでもアクセス可能
protected : このクラスとサブクラスのインスタンスからアクセス可能
private : このクラスのインスタンスからのみアクセス可能
static : Classに紐づくメソッド、インスタンスを作らなくても呼び出せる
抽象クラス
直接のインスタンス化ができない。また、abstractが指定されたメソッドは、抽象クラスを継承したクラスでは実装が必須。
super
小クラスが親クラスのメソッドを呼び出す時に使う。
型としてのthis
抽象クラスを継承したクラスにthisの型が必要なclassを実装している場合、overrideを避けるために、thisを型として利用可能にする。
型エイリアスとインターフェースの違い
(1) インターフェースはプリミティブ型などの割り当てができない (2) インターフェースの拡張は型エイリアスの拡張より厳しく割り当て可能性をチェックする (3) インターフェースの宣言はマージされる
クラスは構造的に型づけされる
構造が同じだと別の名前のクラスでも代入可能・・・・。他の言語だと構造が同じでも名前が違うtypeとしていれば区別されるが、typescriptは構造が同じなら同じ型と認識されてしまう。
mixin
ちょっとトリッキーだが、覚えておくべきコーディングパターン。
デコレーター
mixinを実行時ではなくbuild時に適用するための機能。現時点では例外的な機能で、クラス拡張は可能だが、typescriptの型システムがpropertyの追加などを認識しない・・・。(外部のjsのライブラリがpropertyを使う分には問題ない?)
finalクラスをシミュレートする
constructorにprivateをつける -> 他の関数がextends出来なくなる。
ただし、newでの初期化も出来なくなるので、別の初期化関数(createなど)を定義する必要がある
高度な型
型の間の関係
サブタイプとスーパータイプ
BがAのサブタイプである => Aが要求されるところではどこでも、Bを安全に使うことができる
スーパータイプは、サブタイプの逆。
変性
配列、オブジェクト、関数のサブタイプの判定は難しい。個別ルールなので、気になった時に読み返す必要がありそう。
割り当て可能性
anyは何にでも割り当て可能なので注意
型の拡大
TypeScriptの型推論は、ゆるい推論をしがちなので、より推論の幅を狭めたい場合は、明示的に指定したりconstをつける。
constアサーション
constをつけると、すべてのpropertyに再起的に型の拡大を抑えた形でreadonlyを付与する
過剰プロパティチェック
過剰なプロパティが存在するとエラーになるようなチェックが働く時がある(働かない時もある)
型の絞り込み
合併型のタグによる絞り込みだけ要チェック。
高度なオブジェクト型
ルックアップ型
明かに便利。
keyof演算子
genericsと組み合わせると便利。
Record型 & マップ型
mapに型付けをすることができる。マップ型の方がより柔軟なことが実現できる。
組み込みのマップ型として、Record、Partial、Required、Readonly、Pickなどがある。
コンパニオンオブジェクトパターン
同じ名前を共有するオブジェクトとクラスを定義することができる。
関数にまつわる高度な型
この章はほとんどテクニック。
- タプルに対する柔軟な型推論の仕方
- ユーザー定義型ガイド
- 条件型
- 分配条件
- inferキーワード (難しいので飛ばした。多分一生使わん)
- 組み込みの条件型
エスケープパッチ
非nullアサーションはたまにつかう。(!)で、not nullなことを知らせる。定義時に!をつけることで、明確な割り当てアサーションもできる。
名前的型をシミュレートする
めちゃくちゃ大事なこと言っている。が、大規模すぎるapplication以外ではいらないかも。
プロトタイプを安全に拡張する
interfaceを使うと、prototypeなどの組み込みの機能も安全に拡張できる。
エラー処理
- nullを返す
- 例外をスローする
- 例外を返す (合併型を使う)
- Option型
Option型は特に大変そう・・・。(使う時にちゃんと読めば良さそう)
非同期プログラミングと並行、並列処理
JavaScriptのイベントループ
- メインスレッドからネイティブの非同期APIを呼び出す
- 非同期APIを呼び出すとすでに制御がメインスレッドに戻る
- 非同期APIの操作が完了すると、イベントキューにタスクを格納する
- メインスレッドは、コールスタックが空になると、イベントキューから保留中のタスクを探して実行する
つまり、以下のsetTimeoutは一生実行されない
setTimeout(() => console.info("a"), 1)
setTimeout(() => console.info("b"), 2)
console.info("c")
while(true) {
}
コールバックの処理
JavaScriptの非同期処理は、コールバックを使って表現されるが、型定義から非同期処理であることがわからない。また複数のコールバックを組み合わせ用とすると記述が複雑化してしまうという問題点がある。
プロミス
プロミスのステートマシンは要確認。
型安全なマルチスレッディング
これまでは1つのCPUスレッド上で実行できる非同期プログラムを検討していたが、CPU負荷の高い処理を行うには並列処理が欲しい。
Web Worker (ブラウザー)
JavaScriptでは、workerという機能を使ってマルチスレッドなプログラミングができる。これ自体は型安全ではないが、TypeScriptを使って型安全な形でmessage passingをラップすることはできる。(こういう実装をしたいときに読み返せば十分そう)